
The University of Bristol’s Visual Information Laboratory (VI-Lab) exists to undertake innovative, collaborative and interdisciplinary research resulting in world leading technology in the areas of computer vision, image and video communications, content analysis and distributed sensor systems. VI-Lab was formed in 2010 from a building a collaboration across the Departments of Computer Science and Electrical and Electronic Engineering. It now hosts some 70 researchers – one of the largest groupings of its type in the UK.
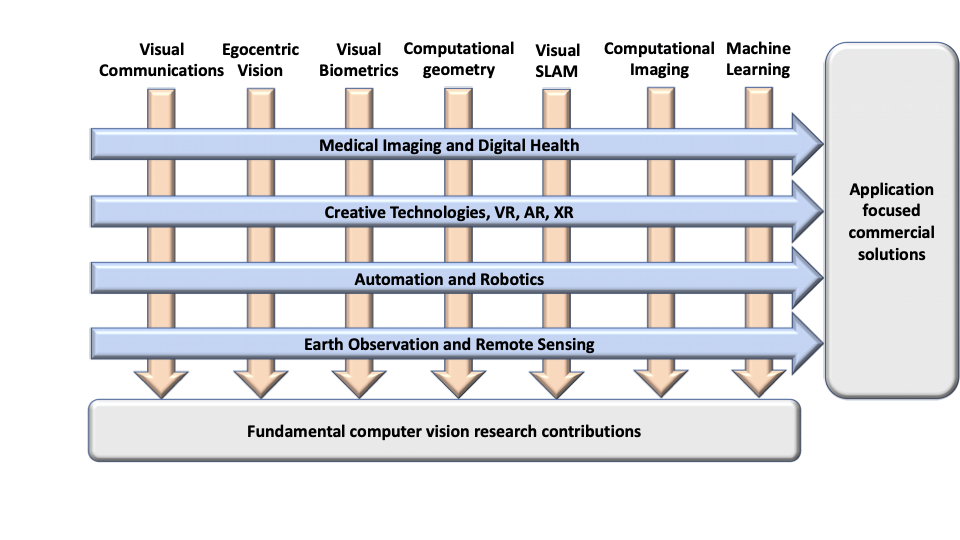
Our research
Further details of our research.